The Data and the Database The DBMS
Raw data is just facts without context, data is fact with context, information is the meaning data interprets. A database is a structured, persistent, self-describing collection of interrelated data, organized according to a specific data model (relational, hierarchical, network, document, key value, graph, etc.), and optimized for efficient storage, retrieval, manipulation, and management. It is not just raw data; it also stores metadata (schema, constraints, indexing, relationships) that describe the logical organization and rules governing the data.
Database is not an application its just a storing mechanism like file. A database management system is a application for managing databases, it act as an interface to interact with data, as one cannot interact with just database cause is just a storing mechanism.
Properties
Data Definition
Involves creating, modifying, and removing structures that define how data is organized in the database.
Data Update
Covers insertion, modification, and deletion of the actual data stored within the database.
Data Retrieval
Selecting data based on specified criteria (queries, hierarchical positions, or relational positions). Retrieved data can be presented directly to users or made available for further processing, either in its original form or transformed by combining or altering existing data.
Database Administration
Encompasses user management, access control, and security enforcement. Monitors performance, maintains data integrity, handles concurrency, and manages recovery from unexpected failures or data corruption.
How DBMS works internally
When the disk is initialised with a partitioning scheme, a partition table is created that tracks where each partition starts and ends in terms of data blocks. when a file system is created on a partition, inodes are created which contain metadata about files and pointers to the data blocks where the file contents are stored. additionally, a super block is created to hold overall information about the file system, such as the total number of inodes and data blocks. a bitmap is also generated to keep track of free and used inodes and data blocks. when a file is created, a free inode is allocated to it, and data blocks are assigned accordingly, as managed through the bitmap.
DBMS just creates file to store data under the hood but the files are organised and there’s manipulation with file to handle data with data blocks.
Architectural layers of DBMS
Architecture (Level) (How data is handled)
View Level (External Schema)
The view level can be described the context in which how data is presented to user. The user can view the data itself not the underlying structure of data description. Aspects like table joins are hidden from the user.
Conceptual Level (Conceptual Schema) (Logical level)
At conceptual level data logic is defined how one filed relates to other, type of data it holds etc. a database is too part of conceptual schema as there are can be many databases inna dbms.
Physical Level (Internal Schema)
Internal deals with actual storage of the data, since data is stored onto the files of the database the file indexing file organisation is handled at this point. DISKS FOLLOWS
Architecture (Tier) (App-DB implementation)
Presentation Tier
The user interface (UI or frontend). Where user is presented with processed data.
Application Tier
Business logic or API processing layer. Implementations of application login init receives user inputs processes it and interact with the database.
Data Tier
The backend database system that stores and manages data.
Architectural components of DBMS
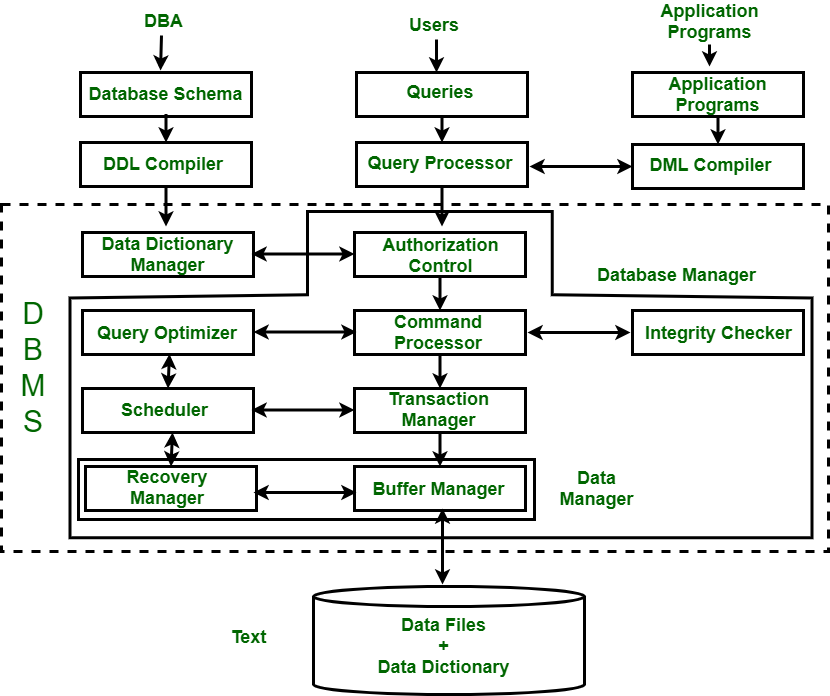
Storage Engine
The storage engine is responsible for physical data layout, page formats, and persistence mechanisms. It manages heap files, clustered and nonclustered index structures, record layout formats, free space management, and page allocation. It implements tablespaces, segments, extents, and block management based on fixed size physical pages. It provides operators for record navigation via row identifiers or tuple pointers.
Buffer Manager
The buffer manager implements page caching between disk and memory. It maintains buffer frames, replacement policies such as LRU, LRU-K, ARC, or CLOCK, and enforces the write ahead logging contract for dirty pages. It supports pinning, unpinning, page latching, and checkpoint-driven flush strategies. It also resolves page level consistency via latch protocols distinct from transaction locks.
Index Manager
The index manager maintains access structures including B plus trees, hash indexes, block range indexes, bitmap indexes, GiST, SP-GiST, GIN, and R trees for multidimensional data. It manages structural modifications, page splits, merges, and rebalancing. It exposes index scan operators with forward and backward traversal as well as range, equality, and predicate-based searches.
System Catalog
The catalog stores metadata including schema objects, constraints, indexes, statistics, privileges, storage parameters, and dependency graphs. Optimizers depend critically on catalog statistics for cost estimation.
Transaction Manager
The transaction manager allocates transaction IDs, assigns logical timestamps or MVCC snapshots, maintains active transaction tables, and coordinates commit protocols. It implements isolation semantics through locking or MVCC. It mediates between concurrency control and recovery.
Concurrency Control Manager
This subsystem implements strict two phase locking, multigranularity locking with intention locks, predicate locking, or MVCC using tuple versions and visibility rules. It detects deadlocks using waits for graphs or prevention via ordering. It ensures read stability, repeatable reads, and serializability depending on the configured level.
Recovery Manager
The recovery manager implements the write ahead logging subsystem, checkpointing, log buffer control, and redo and undo recovery. Engines implementing ARIES perform analysis, redo, and undo based on log sequence numbers, dirty page tables, and transaction tables. It ensures idempotent recovery and guarantees atomicity and durability under system crashes.
Security and Authorization Manager
This subsystem performs authentication, role resolution, privilege checking, row level security enforcement, column masking, and audit logging. It validates each operation against catalog metadata.
Communication and Session Manager
This handles connection pooling, protocol parsing, request framing, session state, cursor management, and network I/O. It integrates authentication protocols and SSL negotiation between application client and database.
Query Processor
The query processor is the architectural component responsible for the full lifecycle of SQL interpretation and execution. It converts SQL text into an internal executable form through parsing, validation, algebraic transformation, and cost based optimization. It generates physical execution plans, selects appropriate operators such as scans, joins, and aggregations, and coordinates their execution with the storage and buffer subsystems. It ensures that query semantics, performance goals, and consistency requirements are met while abstracting the user from the underlying physical data layout.
Aspects
Data Independence
Data independence can be defined as an aspect by which one schema (Lower → higher) is independent of the changes in the other schema. These include:
Logical Independence
To allow changes in the logical schema (tables, relationships) without affecting user views or applications. Sits between External Schema and Conceptual Schema. For example renaming the table name does not affect the query aspects.
Physical Independence
The change in internal schema does not affect the conceptual schema for example adding more disks to system does not affect the schema definitions
DBLC
| Phase | Description |
|---|---|
| Requirements Analysis | Captures functional, nonfunctional, transaction load, data access patterns, domain rules, and performance expectations. |
| Conceptual Modeling | Constructs high-level semantic models such as ER or UML to represent entities, attributes, and relationships independent of platform or schema. |
| Logical Data Modeling | Converts conceptual models into formal structures (typically relational schemas), applying normalization, integrity constraints, and relational algebraic representation. |
| Physical Design | Determines internal data representation: indexing strategies, storage paths, partitioning, hashing, clustering, compression, and file organization. |
| Database Implementation | Deploys the schema, integrity rules, triggers, views, and storage structures on the target DBMS engine. |
| Data Population & Migration | Loads initial datasets, performs data cleansing, mapping, transformation, and consistency validation. |
| Testing & Tuning | Validates performance, concurrency, transaction throughput, query plans, indexing efficiency, and failure recovery readiness. |
| Operation & Maintenance | Continuous monitoring, patching, capacity scaling, backup, replication, security enforcement, and lifecycle compliance. |
| Evolution & Retirement | Refactoring, schema evolution, archival policies, decommissioning, and migration to new platforms or storage paradigms. |